Introduction
I previously wrote a blog post about strategies for reading flat-files (fixed-format, un-delimited ASCII files) to get the flat-file data ready for Tableau analysis. That post was written before I became an Alteryx user.
Alteryx has now completely annihilated my previous work methods by providing far superior workflows that not only dramatically reduce the amount of time needed to get the job done, but these workflows also give me absolute management of the data content being parsed.
This is a preliminary note. This post was written over several days and originally published before the final results were achieved. Now the post has been completed and the full Alteryx workflow is included at the end of this post.
If you like this article and would like to see more of what I write, please subscribe to my blog by taking 5 seconds to enter your email address below. It is free and it motivates me to continue writing, so thanks!
Background
While working in Alteryx, I recently saw that reading flat files is one of the sample files as shown in Figure 1, so I thought I’d give it a shot to dethrone one of my other high-horsepower tools (www.vedit.com). This post describes what I did and the truly unbelievable results that I achieved using Alteryx. Before I deliver the goods, however, you have to look at a few technical details.
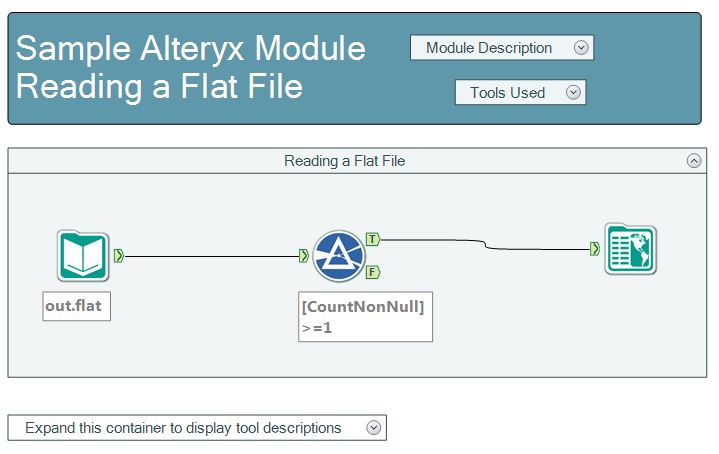
Figure 1- the Alteryx sample for reading a fixed-width (i.e., flat file)
Methodology
The file I wanted to change from a flat file to a csv file could be considered big by some standards. It originates from the medical field and has 420,962 records, with 503 data fields per record, for a total of 211,743,866 fields.The file is just under 2 gigabytes. Each record is exactly 4800 characters wide. The data types included in this file range from strings, to integers, to floats, to mixed-alpha numerics. It is a hodge-podge of information, but it is a very precise collection of information.
An Excel file is sent along with the flat-file so that any user of the data is able to comprehend what is in the file. The Excel file provides the field definitions, their length, the data type, and a lot of other information. Figure 2 shows a subset of that file with a couple of new columns that I created to be able to parse the file with Alteryx. The fields that I created are shown as the Alteryx Data Type column and the Alteryx column. The last column shown is actually the XML code needed by Alteryx to read a flat file. You have to write that XML code to configure each field that you are going to parse from the flat file. Since I had 503 of those field definitions to write, I took the easy way out and let Excel do the writing for me as described below.

Figure 2 – The Excel file shown the content of the first few fields (1-13) and the bottom of the file for fields (501-503).
Figure 3 shows the first few records of this *.flat file, which is an XML file that contains the 503 field definitions after extracting them from the last column of the Excel file shown in Figure 2.
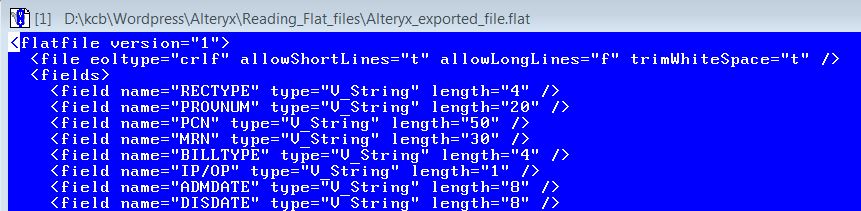
Figure 3 – The first few lines of XML configuration file (*.flat) that was created for the example.
Figure 4 shows the Excel formula (a nested if then else block, a few levels deep, shown at top of graphic) that I used to map the “field type” column that is provided with the data set into the “Alteryx Data Types”column. Alteryx allows the following data types to be read from a flat file: Bool, Byte, Int16, Int32, Int64, FixedDecimal, Float, Double, String, V_String. Since Alteryx does not allow dates to be read and since my file has dates included (see fields 7,8 in Fig 2) I decided just to map them as V-Strings and post-process the file after Alteryx finished. How I did that date reformatting operation is described in detail at the end of this post.

Figure 4 – The Excel formula for mapping the “field type” to an allowable Alteryx data type.
Figure 5 shows the Excel formula (a combination of formatting, concatenation and cell references) that I wrote to properly create the XML fields needed by Alteryx in the *.flat file. The formula was copied down for all 503 fields and then cut and pasted into the *.flat file shown previously in Figure 3.
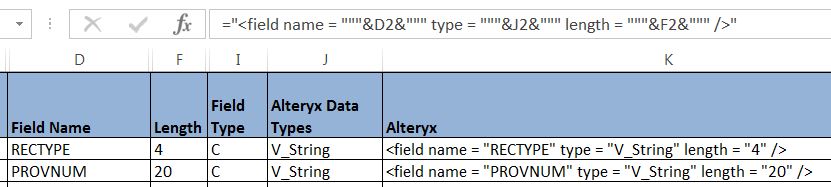
Figure 5 – Excel formula for assembling the components of the *.flat XML file needed by Alteryx.
Once the configuration was complete, a workflow similar to the one shown in Figure 1 was executed, with the 2 Gigabyte flat file being loaded and parsed according to the instructions shown in Figure 3.
Results
I did two tests in this experiment to compare Alteryx to Vedit. In my previous blog post regarding reading flat files, I had shown how fast Vedit did the job compared to a custom VB .net program that I wrote. Vedit blew the VB .net program away. In this case, I tested both Alteryx and Vedit in a head-to-head comparison of parsing every field from every record, or all 211 million pieces of data.
Figure 6 shows the first five records (of 420,962) and approximately the first 15 fields (of 503) of the unaltered input data file. This flat file is ugly and is impossible to read without parsing.

Figure 6 – The first twelve records of the flat file, showing only a few of the 503 fields present in each record (click for a larger view).
Figure 7 shows the first five records after parsing with Vedit. Notice that for null fields Vedit creates a double comma (,,) and for the last two records, which are numerical (currency), Vedit does not strip the leading zeros. The stripping of the leading zeros would have to be done in a post-processing step.
Figure 7 – The first five records of the parsed Vedit file and (click for larger view).
Figure 8 shows the first five records after parsing with Alteryx. Notice that for null fields Alteryx creates a double quote (,””,) and for the last two records, which are numerical (currency), Alteryx displays these properly because the fields were defined in the XML file as double precision numbers. However, for a few records in the file where negative numbers such as (00000-123.45) were found, Alteryx reported errors with those fields and it also had trouble with additional fields in the data like (2,345.23). Alteryx only reported problems on 31 fields out of the 211 million fields. Simply amazing and insightful, which can help you quickly identify potential data problems.

Figure 8 – The first five records of the parsed Alteryx file and (click for larger view).
Now for the reason for this post – the unbelievable result. I’ve been around the block a time or two with XML. I previously elevated my XML skills to expert level for a while to be able to do some really cool work. I’ve written visual XML schemas (click here) that could validate input data for numerical models, and the documentation of how this is done is found in Chapter 2 of this Model User’s guide that I assembled (click here). But I never expected the result that Alteryx provided. Here is the beef, so to speak.
Vedit took 5 hours to process this file. That is over 18,000 seconds. Remember that Vedit blew the doors off of the VB .net code by a factor of a 100 or more. Well, Alteryx processed this file in 28.8 seconds! Yep, that is right, 28.8 seconds (not minutes, just plain old seconds). When it finished that fast, I thought the workflow had a catastrophic error or something.
How is this even possible? How could Alteryx read and parse a 2 Gb file with over 211 million data fields, and write the output file in under 30 seconds? I have no idea! I’m stunned. Impressed. Blown away. This short time means that this workflow is processing at a rate of 7.35 million data fields per second! That is professional-grade software that is highly optimized for the task at hand (my computer has 40 computational nodes, so I need to check to see if this operation uses all of those nodes). That is the REAL DEAL when it comes to processing data. Fantastic job Alteryx, you guys rock! Your XML data reading routines are fantastic!
Recommended Improvements
OK. I’ve sang the praises of Alteryx but there are a few recommendations for improving the workflow process to give you a balanced report on this project. First, Alteryx needs to improve their documentation of the sample cases. As shown in Figure 1, the sample documentation does not provide enough information to a new user like me to be able to quickly find the information needed to complete this work. Once I figured out the steps needed (many thanks to Alteryx tech support, namely Paul Treece), I was able to do everything I’ve shown here in about 20 minutes. To get to the 20 minutes took way too long, however. Here is a list of improvements for Alteryx to consider.
- Put links in the sample documentation page (shown in Figure 1) to the two specific help pages that are needed to execute this work. First, provide a link to the help page that shows the allowable data types. Secondly, provide a link to the page that shows the XML parent and children elements and their allowable fields. Each of these pages are currently too hard to find.
- Using the example provided with Alteryx, the XML configuration file is called “out.flat”. This naming convention is terrible, because this is a user-defined XML file that is needed to process the flat file. A proper name for this file should be something like “flatfile_example_configuration.xml”. The use of the name “out.flat” is extremely misleading and confusing.
-
Along those same lines, Alteryx has named the input file as “out.asc”. This is an input file, not an output file, once again the file naming is very misleading. This file should be called something like “flatfile_input_example.txt”.
-
Lastly, Alteryx needs to include a new property for each allowable field. This field should be called something like “keep_field”. This field would allow users to choose whether to keep this field in the output file or to discard it. In my example, I don’t want to carry the overhead of all 503 fields into my Tableau analysis, so I’d like to pick and choose which fields get carried forward. Technically this upgrade is not needed because in Alteryx you can add a selection tool to your workflow after you parse the file to do the same thing, but this one additional field makes a great deal of sense for immediately eliminating fields that you do not want to carry forward in your analysis or through your Alteryx workflow. When you have hundreds or potentially thousands of fields that you are parsing, it would be nice to have this switch available at the time of parsing rather than as a secondary step because the XML formula shown in Figure 5 could easily be expanded to handle this field. Manual operations such as picking which fields to eliminate can be time consuming for complicated examples.
These recommendations are easy fixes for Alteryx. On the scale of 1 to 100, I’d give them a 95 for the current state of the software. It is incredible! The primary problems left to solve are these (1) getting rid of the extra columns you don’t want in your analysis and (2) fixing the date fields. Problem #1 is immediately solved by adding a selection tool to your workflow after the file is parsed, which allows you to choose which fields you want to send to the output file. I have now added that to my workflow. To solution to problem #2 requires a little more explanation but has also now been added to my workflow.
Using Alteryx to Fix the Date Field Formats for Importing to Tableau
Alteryx should be able to change all date fields in my file that are currently in the form of mmddyyyy to mm/dd/yyyy very easily. By using the DateTime tool, this simple format update could be done for any date fields in my example that were set to strings during the flat file parsing operation. As shown in Figure 9, however, the available formats for this tool surprisingly does not include mmddyyyy. I think Alteryx will be adding the mmddyyyy format to the list shown in Figure 9 sometime in the near future now that I requested it. So until that is completed, I used another method in Alteryx to convert the dates as shown below (with the expert help of Mr. Ned Harding of Alteryx).
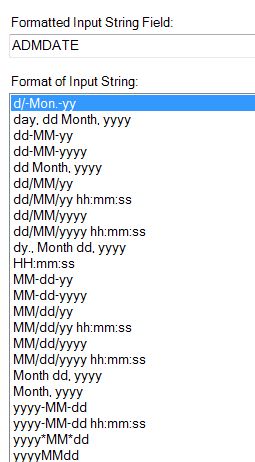
Figure 9 – Available formats for turning a string into a date.
As shown in Figure 10, the multi-field formula tool was used to change the 34 date fields in this database from mmddyyyy to mm/dd/yyyy. For all the selected date fields, the actual conversions are completed with a regular expression match and replace that has the syntax shown in the formula at the bottom of Figure 11. With the inclusion of the date format transformations, the total workflow processing time rose from 28.8 to 37 seconds! This workflow literally has taken a day or two of work with many complications involved and collapsed it down to a few seconds. That is a huge result and one that I am very pleased with!

Figure 10 – The complete workflow for this problem, including the multi-select formula tool used to convert the dates.

Figure 11 – The regular expression formula used in the multi-select formula tool to change the date formats from mmddyyyy to mm/dd/yyyy.
Using Vedit to Fix The Date Field Formats With Regular Expressions
This section is technically no longer needed in this blog post because I have continued to work on the processing of this data in Alteryx and I now have a completed workflow, as I have just shown in Figures 10 and 11. However, I am leaving this section in-situ because it provides an alternative way to process the dates that are in the form of mmddyyyy, without using Alteryx.
As previously shown in Figure 8, the seventh and eight fields are dates in the form of (mmddyyyy), as are 32 other fields. By doing a regular expression search and replace command in Vedit, the dates can be quickly transformed to (mm/dd/yyyy), which Tableau prefers and automatically recognizes. One problem with this operation is that there are other fields in this file that might have the form of (,xxxxxxxx,), where x is any number from 0 to 9. To be able to process only the dates, you have to be clever with your regular expression search and replace. Here is what I used:
Regular Expression Match (find only 8-digit dates in the form mmddyyyy)
,{[0-1][0-9]}{[0-3][0-9]}{[1-2][0-9][0-9][0-9]},
Replacement String (replace the date with mm/dd/yyyy for Tableau)
,\1/\2/\3, <- , replaces , \1 replaces content in first {} ; / is the date delimiter ; and so on until then end
How does this work? Since months can only go from 01 to 12, the first term in the curly brackets limits the first month digit to 0 or 1. This will knock-out any other 8-digit numbers that start with 2-9 (80% of 8 digit possibilities). Secondly, since days only go from 01 to 31, the first day term in the second curly bracket limits the day to 0 – 3, which knocks-out any numbers from 4-9 in this position. Lastly, the first term in the third curly bracket limits the first digit of the year to 1 or 2, since data will be from the second or third millenia. These three exclusions when taken together pretty much assures you that any valid 8-digit date will get changed but the other 8-digit numbers will be left alone. The Alteryx processing method, however, guarantees that only dates are changed because each date field is selectively processed, which makes it the preferred solution in this problem.
So much for your Extract, Transform and Load (ETL) lesson of the day. Hope you enjoyed the post and thanks for reading!



When you check how many CPUs its using, I suspect you will find that it is only 1 or 2. Its just that it is well optimized.
Hi Kenneth,
This a a fantastic post about an amazing too that I use all-day-every-day for all of my data processing and analytical work! It’s fantastic when you compare how long it took to do a ‘process’ before and after and see the often unbelievable time savings.
Your point about getting rid of extra fields – It’s sounds as though you are talking about the Select tool, but I’m assuming you might be referring to something more complex?
And for the date problem you talk about there is a tool in Alteryx called ‘DateTime’ which may solve your issue.
Give me a shout is you need any help or clarification or if you’re problems are more complex than my suggested solution.
Thanks,
Joe
Pingback: Recent Alteryx Web Round-up | Sciolistic Ramblings
Pingback: How to Work With Flat-File Dates in #Alteryx | 3danim8's Blog
Pingback: Strategies for Using Fixed-Width ASCII files with #Tableau | 3danim8's Blog
Pingback: Using #Alteryx To Process Non-Ideal Flat-Files | 3danim8's Blog
Pingback: How To Build An #Alteryx Workflow to Visualize Data in #Tableau, Part 2 | 3danim8's Blog
Pingback: How To Build An #Alteryx Workflow to Visualize Data in #Tableau, Part 3 | 3danim8's Blog
Pingback: Impressions From Our First Month Of Using #PowerBI | 3danim8's Blog