Introduction
I now have a new job. For this reason, I have to learn how to use new and emerging technologies to get things done. I’m using new software and hardware platforms and technologies all the time. I’m making connections between Tableau, Alteryx, Teradata databases, DB2 databases, Aster files, Hadoop, etc.
Although I have used Alteryx and Tableau together many times, I haven’t had to connect them to a multi-pentabyte data warehouse like I’m doing now.
With anything new, there are always things to learn and challenges to overcome. In this article, I’m going to talk briefly about another amazing Alteryx result that floored me yesterday. This topic is how Alteryx can be used to off-load processing to the data warehouse to allow me to get things done efficiently.
The Problem Definition
I now have access to hundreds of Aster database tables that contain data that spans decades of time. There are tremendous volumes of data in these tables. The sizes of these tables range from megabytes to terabytes. The number of fields in these tables varies widely and can be overwhelmingly large.
I could spend a lot of time within any of these files just getting to know what is included. Such was the case last week when I was directed to a file that contained about four groups of information. I was interested in extracting one year of data from one of the groups of information. The problem was, I didn’t know how much information that would be.
To find my answer, I did what I always do. I called on Alteryx to save the day. Although I had never connected Alteryx to an Aster database file like this before, it only took me about 30 seconds to successfully make the connection. This was a pleasant surprise considering what it took me to connect Tableau to the same type of file.
The workflow I developed was fairly simple and is shown in Figure 1. The workflow specified the data connection and returned data to me for the year 2014 and for the category of information I was interested in by using two filters. Once that data was returned, it was joined to some other data to allow me to do the analysis.
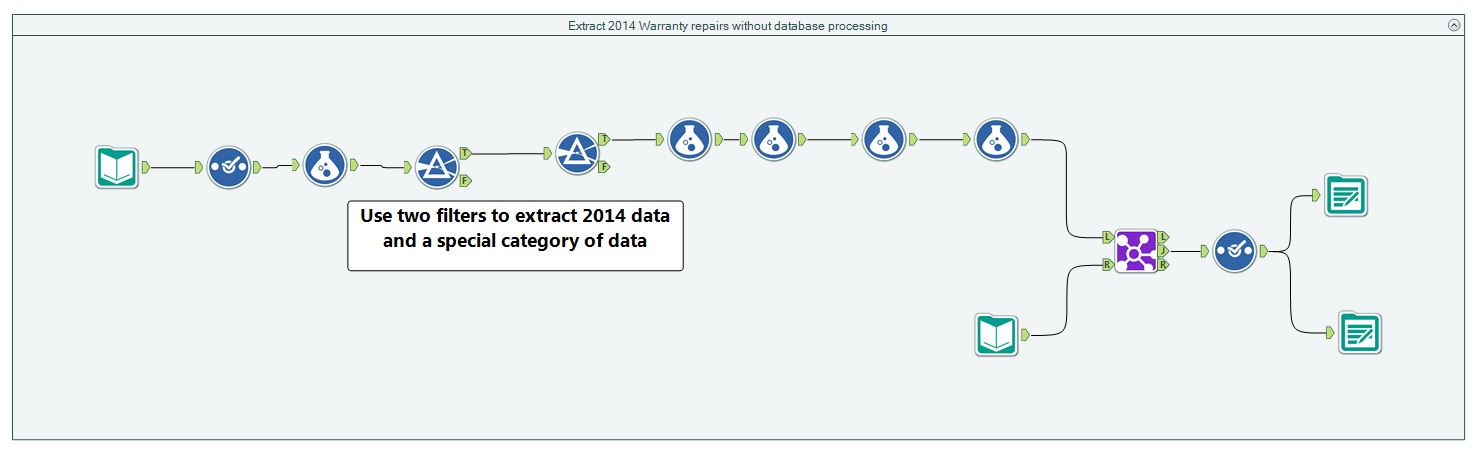
Figure 1 – The original workflow I developed without using in-database processing.
I tested the workflow by limiting the record count to 10,000 before letting it loose on the entire database table. I knew from this initial testing that this was going to take a while to complete. I knew this because this particular table had over 429 million records that had to be processed. So I let it go and 25.5 hours later, I had my results.
Well, 25.5 hours is a long time to wait for results. While it was running, I started thinking about what was happening. I did some research and came across this article from August 2014 that perfectly explained my situation. In the article, Ned wrote:
The difficulty though is that Alteryx is limited to the speed it can read & write data from where it is stored. Having a super fast data processing engine doesn’t help if you have to pull a terabyte of data from a data warehouse only to find a subset of it and produce a report. It doesn’t help to be fast if it is slow to get the needed data.
In my case, my connection to the data warehouse was returning data to me at approximately 3 Mb/sec. When you have to read in excess of 300 Gb of data, this takes a long time to accomplish. Alteryx was not slow in doing what I asked it to do, the connection from me in Texas to the data in Michigan was slow.
The Problem Solution
Based on the article I just referenced, I did further research on Alteryx to find out more about in-database processing. What I learned was that the in-database processing tools were available for Oracle and Microsoft SQL databases in Alteryx version 9.5, but the Aster database tools were scheduled for release in version 10.0. That was both the good news and the bad news all in one statement.
The really great news for me, however, is that there is a really smart guy at Alteryx named Damian Austin that volunteered to work with me for a few minutes yesterday. In less than 30 minutes of working together, Damian showed me how I could implement in-database processing for my Aster files right now. I learned that I do not have to wait for version 10.0 to experience much of the functionality. Essentially, Damian showed me how to use the Visual Query Builder (Figure 2) and the SQL editor (Figure 3) to make my workflow much more efficient.

Figure 2 – The visual query builder settings that can be used to streamline the data sent back to your workflow.

Figure 3 – The SQL Editor that is used to check the syntax of your custom SQL. The last two statements shown here pushed the two filter operations I used in Figure 1 into the Aster database for more efficient and streamlined data movement.
The Results
Once I understood how the tools shown in Figures 2 and 3 were configured and used, I removed the two filters from the original workflow because they were no longer needed. Figure 4 shows the revised workflow that implements in-database processing.

Figure 4 – Compared to Figure 1, the workflow no longer has the two filters near the beginning of the workflow. The effect of these filters has been pushed into the first tool – the database connection.
With these simple changes, the workflow that originally took 25.5 hours was completed in 1.3 hours, as shown in Figure 5! There were 13.5 million records out of 429 million records that got sent back to me to enable me to complete my analysis.

Figure 5 – The time required to complete the workflows shown in Figures 1 and 4.
How and why did this happen? The three in-database processing steps I used included:
- I choose only the fields I wanted to receive from the database into my workflow (Figure 2),
- I filtered the data by date in the database to receive only results from 2014 (Figure 3),
- I filtered the category of data in the database to receive only what I wanted (Figure 3).
These simple operations increased the data transfer efficiency dramatically because the data I received into my workflow from the database was exactly what I wanted. There was no unnecessary data transfer from the big database table into my workflow, like was the case in the original workflow shown in Figure 1.
Final Thoughts
Tools like Alteryx and Tableau are tremendously versatile. The versatility of Alteryx is exemplified in this example. Alteryx is a tool that can be used today to connect to large data warehouses and use the intrinsic computing power of the data warehouse to surgically extract a subset of data to answer a specific question. Companies that are using big data warehouses should look to Alteryx as a tool to allow them to interact with their data in this highly efficient and optimized fashion.



Hi Ken – the standard workaround in Alteryx would have been to use the Dynamic Input to pull out the subset of the larger table once per ID in the smaller table. This would have sped up the first workflow considerably – but agree that the IN-DB tools are a valuable addition. Look forward to meeting you next week!
Hi Chris,
Damian and I discussed two approaches to improve this workflow. One was using the dynamic input tool as you suggested. The other was the technique I wrote about. We ran out of time to cover the dynamic input tool approach. I explained to him that I had not been able to find a good example of this tool to understand its usage. Maybe I’ll do that technique and compare the results! Thanks and I’ll see you in a few days!
Ken
Yes I did promise to write a Dynamic Input blog and it’s still on my list! I’ll give you a demo in Boston 🙂
Why not just use a live Tableau database connection? Seems like you’d get similar “visual” join tool. And issuing efficient queries is Tableau’s bread and butter.