Introduction
In this article, I discuss the usage of the fuzzy matching tool on a real-world example. I have wanted to try this tool to see how it works and to determine if it could help me solve a problem that recently came my way.
The Problem
I recently was given two different databases that contain employee names. The source databases are not connected in any way. The employee names are not connected by a unique field. This case seemed like a good chance to use the fuzzy matching tool.
My objective is to match records based on the employee name (and another field). To begin the task, I needed to see if I could match employee names.
I have employee names that may have variable spellings, may contain middle names or initials, may have designators like Sr, Jr, III, and have two totally different native formats.
This example set is full of real-world complexity partly for these reasons and partly because of the cultural diversity of the company from which the data originated.
Database 1: Last Name/First Name [Middle Initial | Middle Name | Nothing at All] – 24,376 employee names
Database 2: Last Name [Jr | Sr | III | Etc], First Name [Middle Initial | Middle Name | Nothing at All] – 16,057 employee names
Figure 1 shows two very simple example records, with the first column coming from the first database and the second column coming from the second database. You can see that in the first record, the first database uses Jr and the second database doesn’t. In the second record, the middle initial is used in one case and the full middle name is used in another. There are countless variations on these themes in these two databases, including having trailing spaces at the end of some employee names.
Figure 1 – Two example records showing name format differences and spelling differences.
The Fuzzy Match Methodology
I reformatted the employee name databases so that both databases had the same comma-delimited format. Once I had these two files ready, I built an Alteryx fuzzy match workflow by closely following this excellent 10-minute Alteryx training video which was incredibly valuable to my use case.
My workflow is shown in Figure 2. Since the details of what I did is so well explained in the video, there is no point in me rehashing the approach. However, you do see the use of the regex replace tool to eliminate those pesky end-of-line spaces that exist in each database. This just helps eliminate some of the variability in the names.
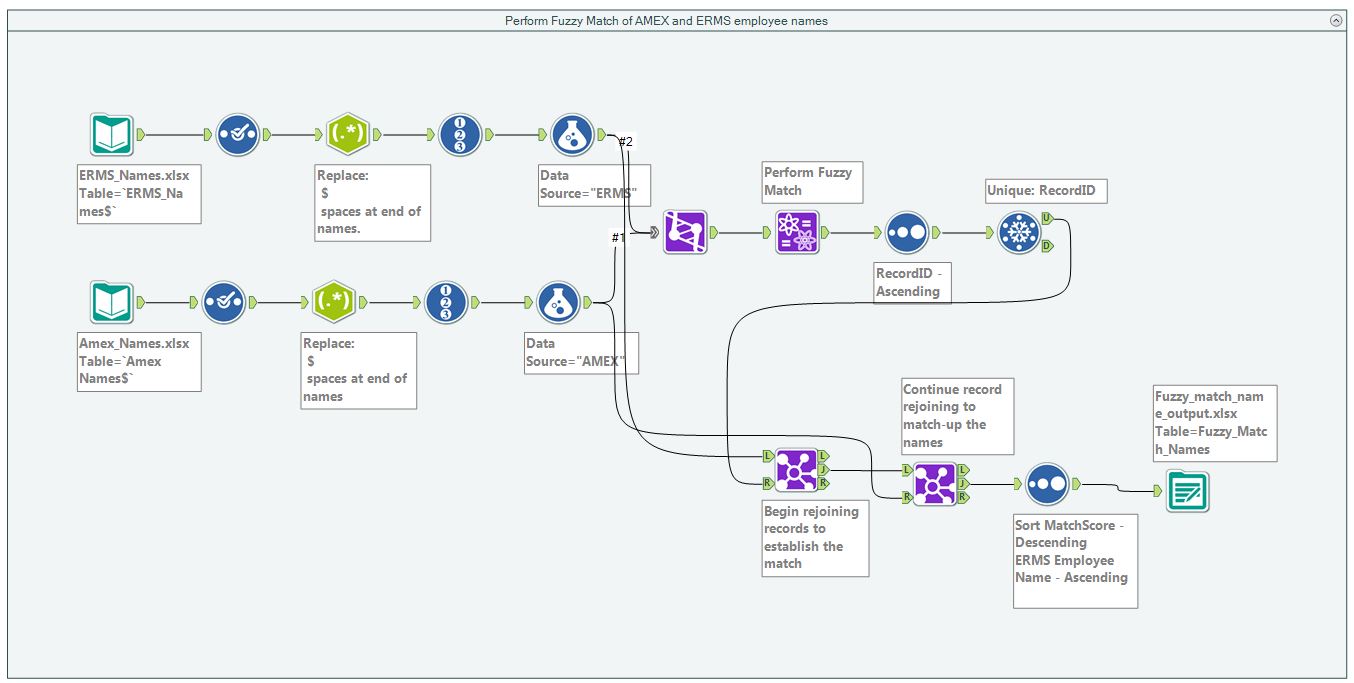
Figure 2 – Alteryx workflow to perform fuzzy matching of employee names.
I was planning on doing a detailed benchmark type study of this algorithm, but I ran out of time. [Note 1 Year Later: I did the benchmark study (click to view)].
I ended up trying three different settings for the fuzzy match tool as recommended in the video. The remainder of this article will be about what I learned from this experience when I used the most advanced settings shown in the video.
The Results
From the two lists, the fuzzy match tool was able to match 15,280 names at a level of 80% or above (out of a theoretical maximum of 16,057 names, or 95%). What I am going to show is a detailed assessment of the value of these matches.
Post-Processing the Matched Results
Figure 3 is a histogram of the match scores from this incredibly diverse data set. The match score represents the degree of confidence in the match, with a score of 100 representing the highest confidence achievable. Nearly 50% of the names (about 7,100 people) were matched at the 100% level.
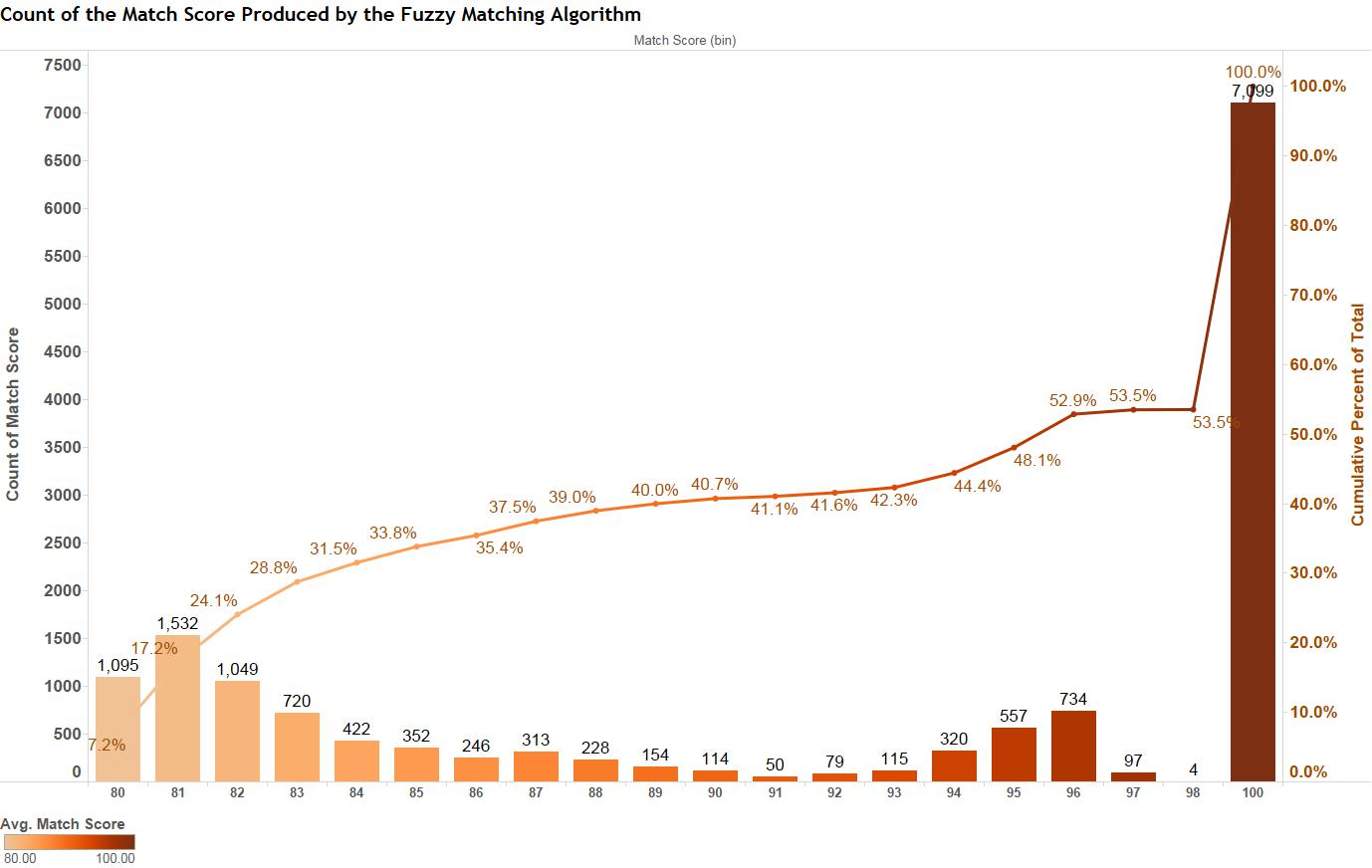
Figure 3 – Histogram of fuzzy match scores and the cumulative percent of the total count.
By comparing the match scores to the detailed list of names that were matched, I was able to do some quick work to see where the matching began breaking down. To examine this in a little more detail, I used a couple of tricks to gain some insight.
First Method of Analysis
I broke the two name strings down into two parts including last name and first name. I suspected that to get a 100% match, I would see at least matching last names from each database. Figure 4 shows the same histogram as Figure 3 but now with colors to show when the last name matched. Much to my surprise, there were 197 records that were scored as a 100% match but the last names didn’t match! How could that be, I wondered?
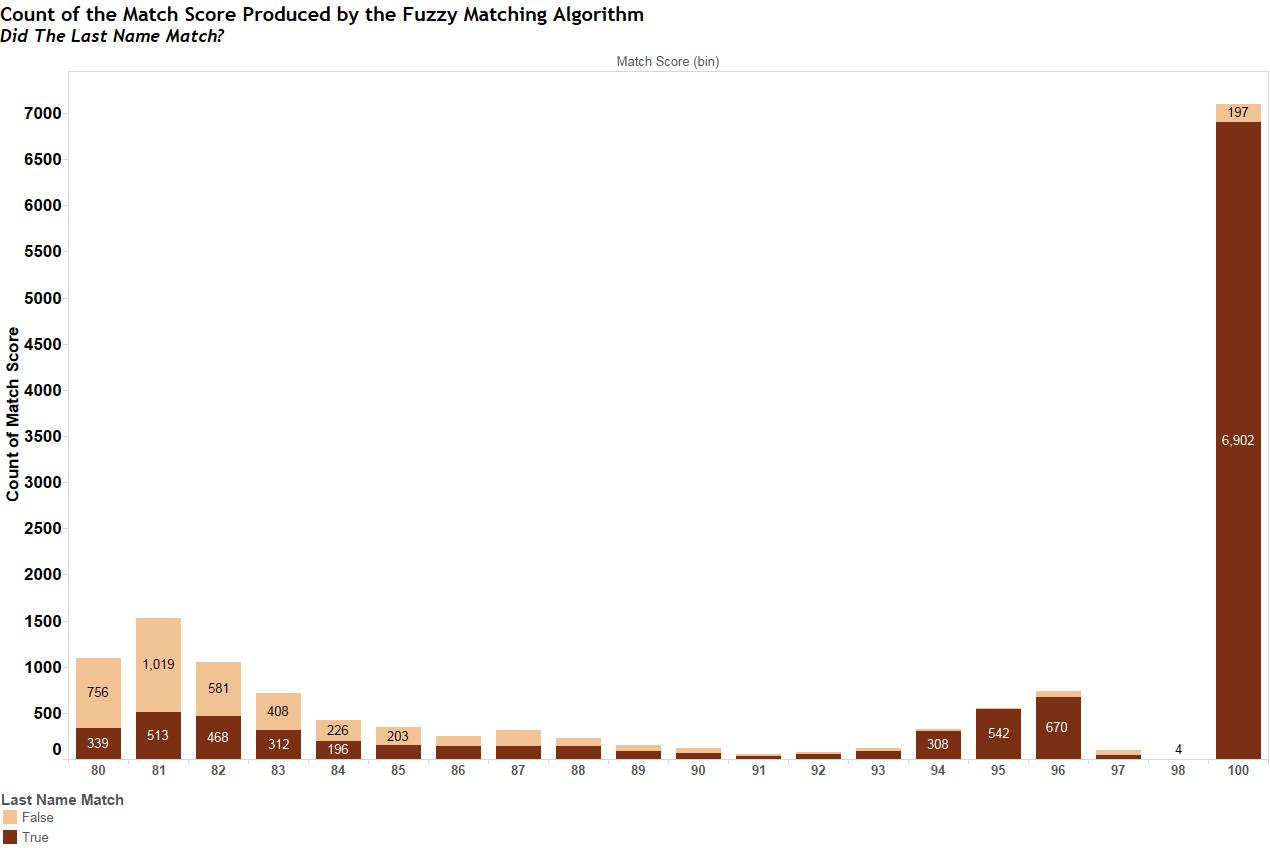
Figure 4 – Histogram showing the count of records where the last name matched in the two databases.
To examine the records that were a 100% match but had different last names, I generated a table to compare the records.
Figure 5 shows the table for about 20 of the records that had a 100% match. When you review these results, the brilliance of the fuzzy matching algorithms begins to be seen. You can see that indeed all of the people match (all 197 via visual inspection). You can see that spaces in the names are accounted for, Jr/Sr’s are accounted for, and even the swapping of the first and last names are accounted for. To me, this is a superb result and gives me great confidence is using the 100% matching records. If I really wanted to understand the rules that were used to make the match, I could decipher the “match key” column that is produced by the algorithm.
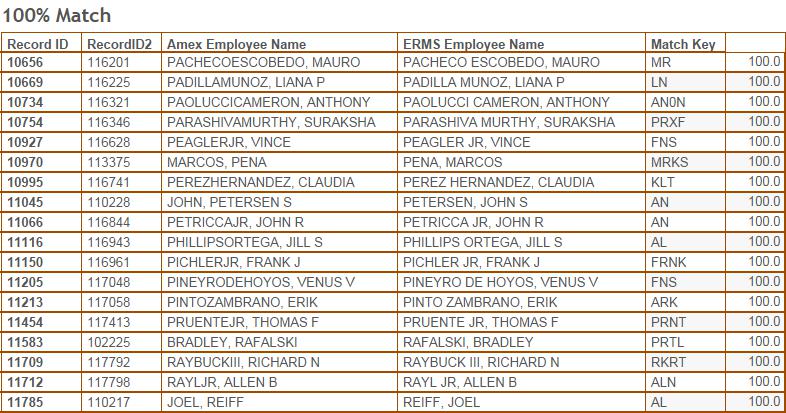
Figure 5 – About 20 records that had a 100% overall match but the last names didn’t exactly match.\
Second Method Of Analysis
Once I had the Tableau workbook set-up that created Figure 5, I simply added a quick filter for the match score so that I could see when the matches began breaking down. I included all records in this analysis. I quickly produced tables for each match score from 98 down to 80. This work was so fast because Tableau is so fast in creating these tables. I simply had to scan each table to see when the matched names began deviating from one another.
Figure 6 shows twenty records of the 90% match results and Figure 7 shows twenty records of the 85% match results. By using my brain as a rapid comparison tool, I determined that the match results are fairly solid through 90%. The results are very reliable. Once you go below 90%, more mis-matched names occur as shown in Figure 7.
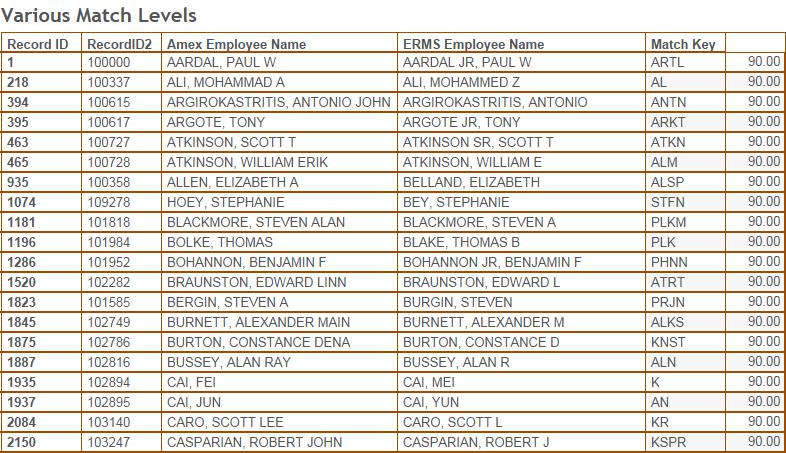
Figure 6 – Name matches at the 90% level.
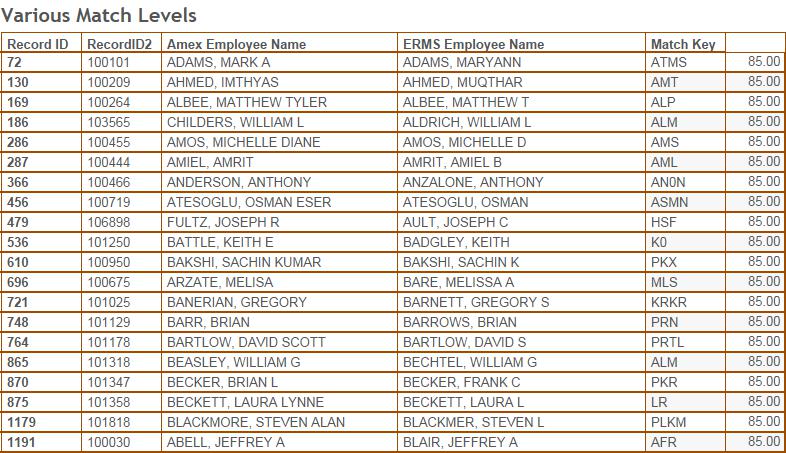
Figure 7 – Name matches at the 85% level.
Therefore, I used the matched names that were 90% or above in my analysis and got great results. This meant that I had 60% of my database available to me in matched format (about 9600 people). It turned out that this was sufficient for my purposes and I didn’t have to dive deeper to improve the match results, but I could have if I wanted to.
Final Thoughts
The name spelling variations present in these files is very large, with employees representing many countries around the world. The typos and other mistakes made in the two databases were enough to drive most sane people crazy, including swapping the first and last names.
However, Alteryx came to the rescue again and provided to me a working database that allowed me to complete what I wanted to do in another, more complicated workflow.
Fuzzy matching is fuzzy by definition. You don’t get 100% matched results. It isn’t expected and it isn’t possible with data sets like I showed here. However, using this tool has allowed me to see this data more clearly now and will likely be a tool that I revisit in the future.
Update Many Months Later
Well, little did I realize at the time, but the final sentence of this article came true about a year later. I just published part 2 of this article, which examines how the fuzzy matching algorithm selections can influence your results. Click here to read that article.



Pingback: Benchmarking the Alteryx Fuzzy Matching Tool | 3danim8's Blog