Introduction
A few months ago, I took a deep dive into the capabilities of the Alteryx Fuzzy Match tool. I completed this testing to better understand the options available in the tool. This tool is used to find non-identical duplicates in a data stream.
Background
Last year I wrote an article on the use of the fuzzy match tool to find matching names across two different databases. This article is an extension of that work (the same data is used here) and goes into significant detail about the parameter selections that are available in the tool. As shown in Figure 1, over 20 Alteryx workflows were completed during the sensitivity testing of this tool.

Figure 1 – The Alteryx workflow files stored during the sensitivity testing of the fuzzy matching tool.
The file naming I used in Figure 1 is a good indicator of what each realization (Alteryx workflow) tested. This list, combined with my working notes (Figure 2 and Figure 3), have allowed me to write this article.

Figure 2 – Working notes for the fuzzy match sensitivity study (part 1).

Figure 3 – Working notes for the fuzzy match sensitivity study (part 2).
Testing Framework
There are a number of fuzzy parameters that can be set for a study like this. Figure 4 shows the main fuzzy menu that is used to set custom algorithm selections.

Figure 4 – The fuzzy match parameters that can be set for customization.
Figure 5 shows the key generation parameters that can be selected. This study tested None, Double Metaphone, and Soundex.
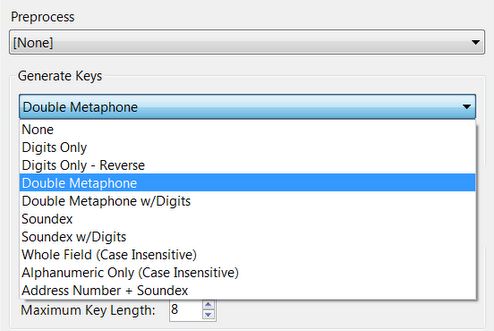
Figure 5 – the Generate Keys options available in Alteryx.
Figure 6 shows the match functions that can be selected. This study tested at least five of these match functions, as will be shown in the final section of this article.

Figure 6 – The match function selections available in Alteryx.
Sensitivity Analysis
There were two types of sensitivity analyses that I conducted in this study. First, I compared the generate key functions (Figure 5), including the none, double metaphone and soundex algorithms. The latter two methods are two of the most commonly used methods for fuzzy matching. The second analysis examined five different match functions (Figure 6).
Results Part 1: Double Metaphone Vs Soundex
Being a thorough data dork does have it’s advantages at certain times. This is one of those times.
As shown in Figure 7, I compiled all the results into one huge data source and threw that data into Tableau. The compiled data formed a 47 MB Excel file that allowed me to thoroughly understand the advantages and disadvantages of each control Alteryx gives us to use in the fuzzy match tool.

Figure 7 – The Excel results and Tableau files created to perform this analysis.
As shown previously in Figure 2, I ran 6 or 7 iterations in each method. These iterations investigated the sensitivity of using keys or not using keys, and the maximum key length. The time required for each test to run is shown in Figure 2. If you don’t use a key, both of the algorithms are very fast (<30 seconds), with Double metaphone being faster in every case.
If you use choose to generate keys for each word, the run times can vary dramatically, ranging from about 4.5 minutes to over 35 minutes. For my example, the optimal maximum key length appears to be 8. This is likely a function of the type of data I used and may not be a general finding.
Based on this first sensitivity test, I determined that the double metaphone with no key generation gave me the best results possible, as shown in Figures 8a and 8b.
Another noteworthy result shown in Figure 8 relates to the use of a key. The two tallest bars occur in the lowest match category when key generation is used. Upon reviewing these results, however, the 46K plus matches are nearly all hogwash. There is no need to use a key for this application. All it does for you is make a bunch of low-level matches that are meaningless.

Figure 8a – Results of the double metaphone vs soundex sensitivity analysis, for key lengths of 2 through 12.
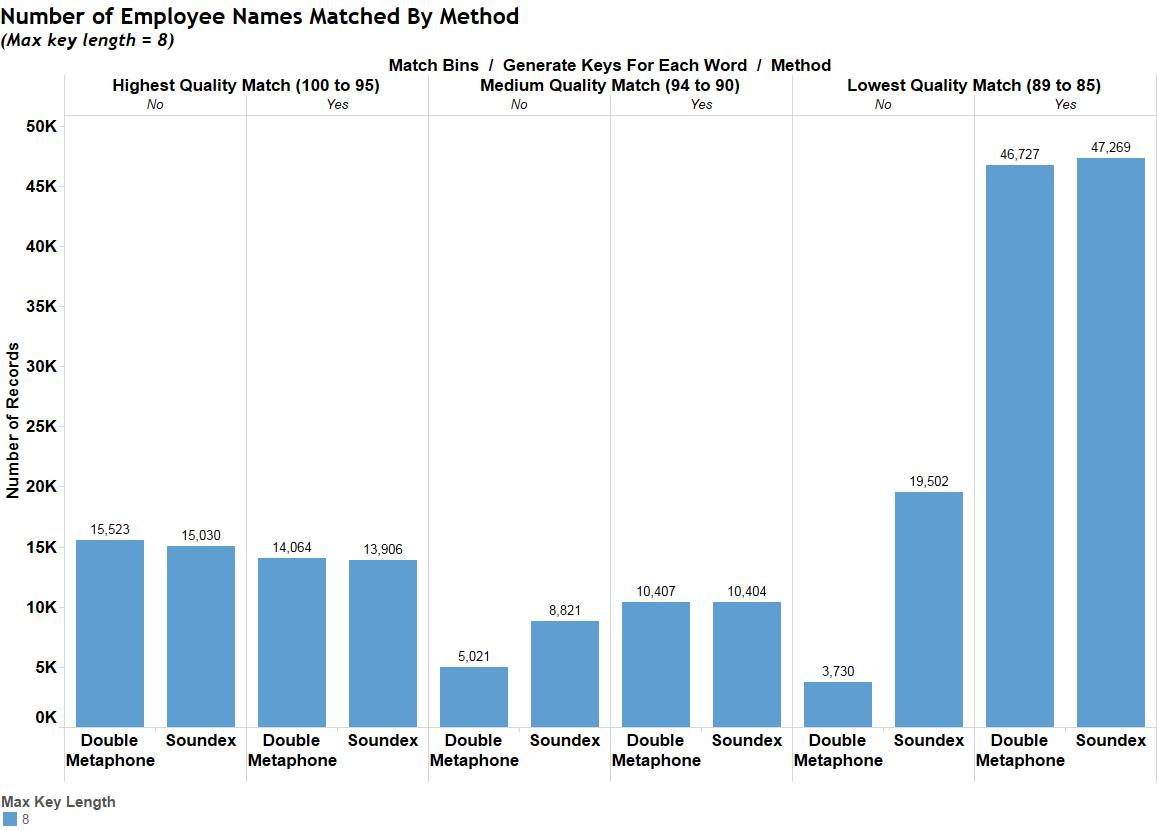
Figure 8b – Results of the double metaphone vs soundex sensitivity analysis, for key length of 8.
Figure 9 shows the results for the best combination of parameters I could develop for this complicated name comparison data set. These results indicate that I was able to reliably match about (35.5%+11.5% = 47%) of the names in the data set. As I explained in the first article in this series, the lowest quality match category (match = 89 to 85) has too many false positives for me to use these results.

Figure 9 – Matching results for the optimal fuzzy match settings. Note that the key length is set to 8 in the input box, but no key generation was used to achieve these results.
Figure 10 shows histograms of the number of name matches by name length (number of characters) for the optimal settings shown in Figure 9. The maximum length in the data set is 48, with seven words in the name! Wow. I wouldn’t want to spell that name on every test I took in school!
Notice that the maximum name length that was matched in the top 2 categories was about 40 characters.
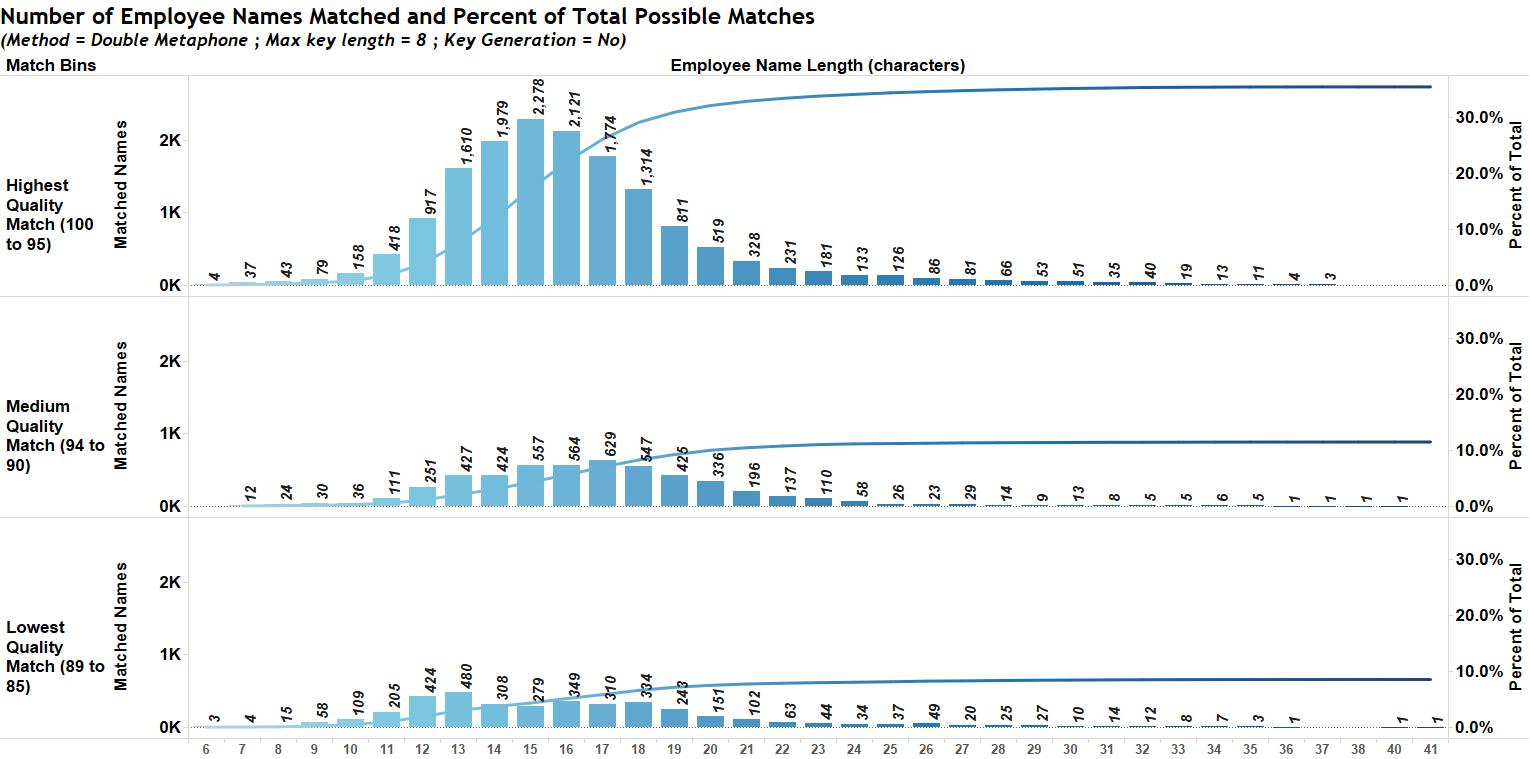
Figure 10 – Histograms showing count of matched names as a function of employee name lengths.
For the fun of it, I created a short video to demonstrate the name complexity that exists in this data set. If you are so inclined, watch the video to see how minor differences in names can lead to lower match scores.
Results Part 2: Match Functions
The second sensitivity test conducted was completed in 5 iterations. This series of runs tested the choice of the match function, using a base case of double metaphone with no key generation, max key length = 8.
As shown in Figure 2, the run times for all the match functions were within 1 second of each other. The results for this test are shown in Figure 11. The Character: Jaro Distance produced the highest number of high-quality matches, so this would be my preferred method.

Figure 11 – Match function sensitivity analysis results. All cases were run at the optimal setting of double metaphone, no key generation, max key length = 8.
Final Thoughts
Fuzzy matching can be a bit fuzzy to understand, so I decided to do these tests to make sure I wasn’t overlooking something when using this tool. I think I now have a better idea of how to use the tool reliably and with better confidence.
I don’t think these results would be the optimal settings for certain types of fuzzy matching, but for name matching, they definitely would be a good starting point.



Pingback: Using the #Alteryx Fuzzy Logic Tool To Find Matching Names | 3danim8's Blog
Another interesting post, Ken. I haven’t had a need for matching like this in quite a while, but it’s great to see that Alteryx has a number of fairly straightforward methods I can employ. I may need to find a reason to use them. 🙂
Hope you’ve been well.
Nice and detailed article Ken.
Now do one on Flookup for Google Sheets… especially for those among us who want power on a budget.