
Introduction
Where there is a will, there is a way. Sometimes the will comes in the form of really talented co-workers like Lew Goldstein.
This is only an introductory article but it does contain some interesting findings. We expect to write more on this in upcoming months.
Connecting Tableau and Alteryx to IBM Big Insights
If you were to ask the Alteryx product team if it is possible to use their product with the version of Hadoop called “IBM BigInsights”, the answer would be: “No, it is not a supported product”. Tableau, on the other hand, does list this as a supported data connection.
One day in May 2017, my buddy Lew gave me a call and said he was having some issues using Hadoop with Tableau. As he explained the problem, I had the solution since I already had detected and debugged this problem before. As we have done many times in the past, we began a collaboration that afternoon that ended up with a very pleasing result. I love when this happens because our skill sets are diverse enough to make us a formidable team.
Not only did we solve Lew’s problem, we went deeper than that and discovered that Alteryx can be used with IBM BigInsights. The secret to that has to do with ODBC driver compatibility.
The Necessary Driver
The key to connecting Alteryx to IBM BigInsights Hadoop is to install the Hortonworks Hive 64-bit ODBC driver. Here is the link for a Windows 64-bit driver. Click here for a list of other drivers for other operating systems. This is a great driver that works with both Tableau and Alteryx.
Tableau Power With Hadoop
Lew has been able to write custom SQL scripts that use regex and other supported features of Hive that mimic the in-database processing capabilities of Alteryx. This means that he is offloading the heavy lifting into Hive, so that the only aggregated results sent back to Tableau because this is what he needed.
This makes Tableau very efficient in working with Hadoop, with very peppy dashboards. The blue text shown below is a custom script Lew created to pull some specific data from Hadoop into Tableau. Within this script, the usage of regex is shown near the bottom of the script.
SELECT
met.exec_date, met.logfile, met.user_id,
COALESCE (usr.name, met.user_id) as sas_user,
COALESCE (usr.country, ‘UNKNOWN’) as country,
met.server,
met.PROC AS sas_proc,
count(met.PROC) as sas_proc_count,
count(met.logfile) as nbr_of_sessions,
sum(met.real_time) as s_real_time, max(met.real_time) as m_real_time, avg(met.real_time) as a_real_time,
sum(met.user_cpu_time) as s_user_cpu_time, max(met.user_cpu_time) as m_user_cpu_time, avg(met.user_cpu_time) as a_user_cpu_time,
sum(met.sys_cpu_time) as s_sys_cpu_time, max(met.sys_cpu_time) as m_sys_cpu_time, avg(met.sys_cpu_time) as a_sys_cpu_time,
sum(met.memory) as s_memory, max(met.memory) as m_memory, avg(met.memory) as a_memory,
sum(met.os_memory) as s_os_memory, max(met.os_memory) as m_os_memory, avg(met.os_memory) as a_os_memory
FROM
adv_analytics.sas_workspace_metrics met
LEFT OUTER JOIN adv_analytics.ad_users usr
ON met.user_id = usr.tpad_id
GROUP BY
met.exec_date, met.logfile, met.user_id, usr.name, usr.country, met.server,
met.PROC;
SELECT
access_date
, regexp_extract(a.filename,’^/.*?/.*?/(.*?)/’) as tenant
, a.user_id
, COUNT(*) as cnt_files
FROM
adv_analytics.sas_storage_metrics a
WHERE regexp_extract(a.filename,’^/.*?/(.*?)/’) not in (‘sas94′,’sasdepot’)
GROUP BY access_date
, regexp_extract(a.filename,’^/.*?/.*?/(.*?)/’)
, a.user_id;
The primary issue we had when working with Hadoop data in Tableau is that Tableau is very sensitive to the format of the date fields. There were a couple of different date fields in the original table which caused Tableau some difficulty. We think the newest dateparse function (Tableau 10.3) will take care of that problem, although this issue was handled by Alteryx with only warning messages given (see below). Note that version 10.3 was not available when we did this work.
Alteryx Power With Hadoop
The connection of Alteryx to Hadoop occurred directly after we installed the 64-bit Hortonworks Hive driver. The only odd behavior we detected was that we were not able to browse the Hive folder tree structure. We had to type the word “Hive” into the Alteryx visual query builder environment to trigger the loading of the tables. Once we did that, the tables were populated and the visual query tool worked as expected.
As shown in Figure 1, we built a simple workflow to perform an aggregation of some data in Hadoop.
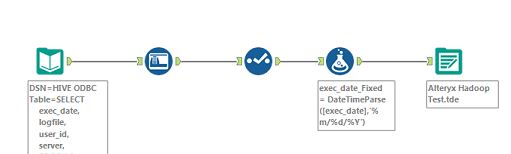
Figure 1 – A simple workflow to perform some aggregate operations in Hadoop.
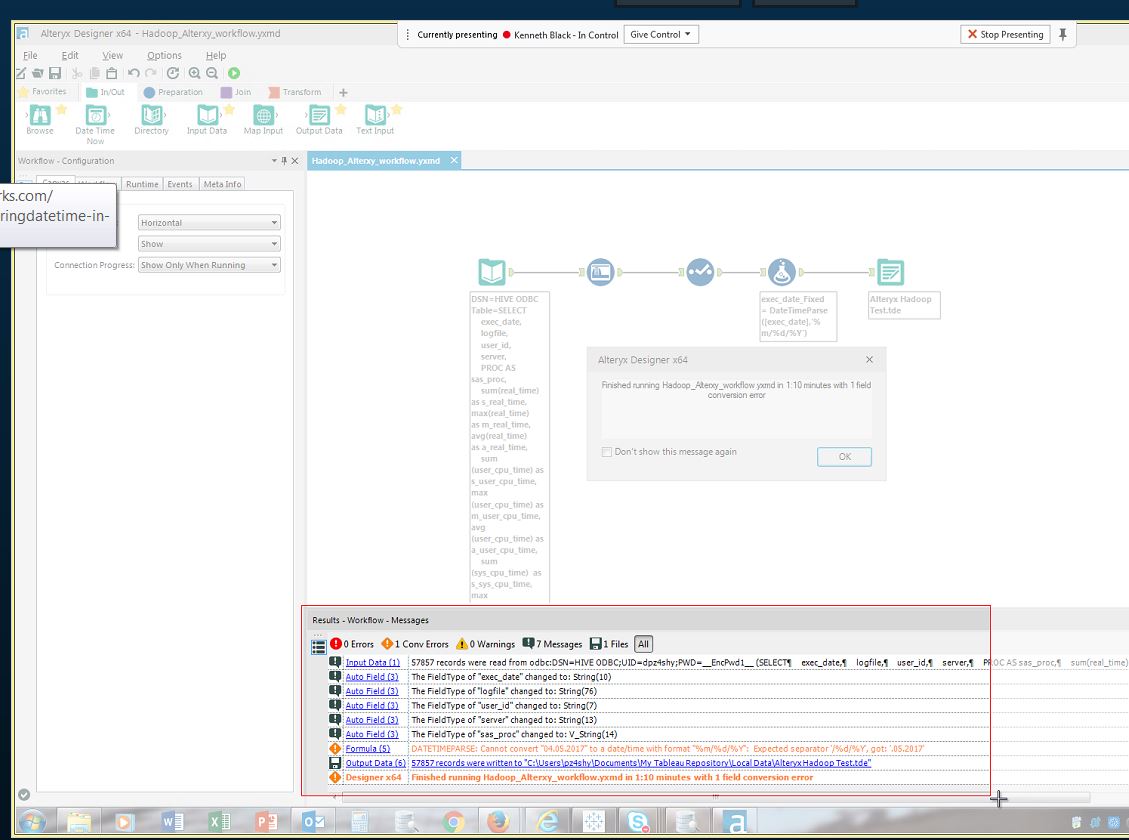
The results of this workflow are shown in Figure 2. The table we queried had 13,601,301 records, which were summarized to 57,857 records in 1 minute 10 seconds. The date format variation did trigger a warning message as shown in Figure 2.
Final Thoughts
This work represents only a few hours of testing during an afternoon, followed by some production work by Lew. I am sure we will be writing more on this topic as we explore the possible connections between Alteryx, Tableau and Hadoop, so subscribe to the blog if you want to follow future work.
In an interesting development, we hear that IBM is moving away from their own distribution of Hadoop and will begin supporting Hortonworks. It seems that BigInsights is a modified version of the Hortonworks release, which is probably why this particular driver was compatible. Hey, since this unexpectedly worked with our version of Hadoop, maybe it will work with yours, too!



Great info Ken! We’ve found that the Hortonworks Hive driver also works just fine connected to Cloudera Hive for Alteryx/Tableau. If you are using Impala, you will need the Cloudera driver.
We’ve found the best benefit of Alteryx with Hadoop though comes via the In-Database toolset (currently supports Hive, Impala and Spark). The ability to quickly build a workflow visually in Alteryx and then have all the processing done on my cluster is a real time saver – especially when you need to summarize several billion records. In Alteryx you can specify different read/write drivers for Hadoop In-DB, so people should check with their tech teams to see what the preferred write format is (Hive tables, CSV, or avro) and pick the right driver accordingly. You may also have to customize the connection string if your cluster is using resource pools.
Jason,
Thanks for adding those keen insights. I think that by sharing these types of insights, the combination of Alteryx and Tableau can be used very effectively to perform quantitative and visual analytics on data stored in Hadoop. Thank you very much.
Ken
IBM uses the base ODPi which is a subset of Horton Works arms dealing. Yes, the recent announcement is very exciting for me as well. Currently we use Simba Drivers via ODBC and I recently started working with Alteryx/Tableau in conjunction with our hadoop system.
We also try/suggest to also keep processing in hadoop with IN-DB tools and creating aggregates (CTAS or similar) to later pull to Tableau or structure the data in a way to avoid joins and provide single aggregate views for direct queries.
Some of my would be cool wish list for this combination of tools.
ODBC works fine but…
native jdbc drivers for hive
python connector for Spark
True Query builder – visual query builder is great but something more built in that is an easy to use and quick query builder off the metastore would be great.
Thanks for keeping us all informed!
Chris