
Introduction
One of the great things about Alteryx is that it never stops surprising me. As I have grown throughout my career, I have been able to continue to learn new things in Alteryx when the time is right for me. This indicates to me how mature Alteryx is as a software package.
In this article, I will explain some additional Alteryx Big Data techniques that make quick work of extracting information from Big Data projects. In a sense, this is part two of my initial big-data article from late 2017. Click here to read part 1 of this series.
Background
Everyone loves to collect data. It is happening everywhere. One of the problems we face, however, is using these ever-increasingly massive data sources. As the size of the data grows, so does the processing time.
Just because you have the data sitting on a hard drive somewhere doesn’t mean it is going to give you instant value. The value is only obtained if you can quickly retrieve exactly what you want, when you want it. Nobody likes to sit around waiting for hard-drives to spin enough times to send you some data hours later. Sometimes you have to surgically extract a portion of the data to complete your analysis. That is what I do in this article.
A Big-Data Collection Framework
Let’s set-up a conceptual big-data collection framework for this discussion and to demonstrate the techniques I discuss here. Here are the details of this hypothetical data collection system that leads to big-data.
- Assume that multiple weather monitoring sites are being used to collect the data. In our example, think of the worldwide weather station monitoring network represented here, with tens of thousands of stations being used to collect data.
- Data is being collected over time, with many measurements per day. Think of thousands of daily wind or temperature readings that are being made with electronic equipment that can continuously record data and record it down to the second.
- Think of an example where you might want to examine the weather data from a series of stations you select for a period of time. Maybe you want to correlate some other non-weather events (i.e. attendance at sporting events) to this weather data.
The question quickly becomes: Can I prepare and store the weather data in a format that will allow me to retrieve what I want with efficiency and accuracy? Can I easily extract hourly temperature or rain data, when the data is stored at the hour:minute:second level of detail? You have to be truthful with yourself when answering those questions because you are going to have billions of records of weather data to query.
Defining the Problem
The weather station data example introduced above stores data as discrete events that have starting and stopping times. During these discrete events, the wind speeds or temperatures might be continuously recorded such as between 1:05 pm to 1:15 pm. This ten-minute period represents one record in your database and it might contain a statistical summary of the variables during that segment in time. Another event might be triggered and the data gets stored from 1:28 pm to 1:41 pm.
Throughout the day, these types of events get recorded and you end up with a variable number of daily events from each of your monitoring stations. Given enough time and enough monitoring stations, you end up with a massive database of weather events that span many days, months, years, and decades.
Now the challenge is posed to you. Someone gives you a listing of monitoring stations, dates, and specific times. These events represent something that happened in the original data. Maybe the event is the peak wind speed or max temperature. In any case, they ask you to retrieve the original event data that corresponds to the points in time they have given you.
In effect, they have asked you to find a series of needles in a giant haystack. The video shown below describes this situation and provides a visualization to help you realize the complexity of the problem.
Data Preparation Strategy #1 – Controlling the Level of Detail
In our example, let’s say that we want to be able to rapidly retrieve weather data from a series of monitoring stations for any given day. What this means is that we somehow want to be able to set the retrievable level of time detail to the day level. We still want all the precision in data readings, so we don’t want to do some form of pre-aggregation on the date/time before storing the data.
At each station, there might be hundreds or thousands of such readings available for wind, rain, temperature, etc. This means that there may be billions of records to search through. To efficiently retrieve the selected daily data, you have to think about how it should be stored to achieve your objectives.
In this case, I will introduce a new column into the data that represents the day the reading was taken. Figure 1 shows how this is done in Alteryx when you have a date/time field called [Event_Date].

Figure 1 – Setting the level of time/date equal to the day. Note that I have chosen to have this field be a date type, but it doesn’t have to be. I can choose to have this be a string, if desired.
In general, there are many use cases where you might want to control the level of detail for your studies, whether it be for data retrieval or for performing aggregations with your data. Figure 2 shows 14 methods of setting the date/time level of detail in Alteryx, ranging from centuries down to minutes. Click here to retrieve an Excel workbook that contains the Alteryx workflow and input/output data for this example. All you have to do is save the Alteryx XML script to a file to be able to use this.

Figure 2 – Formulas to set the level of date/time detail you might need when working with time series data.
When this is applied to some sample data (first three columns), you will see results like those shown in Figure 3 (click for high-resolution graphic).

Figure 3 – These results show you it is possible to control the level of detail when you have a date/time field.
Data Preparation Strategy #2 – Creating Calgary Files To Hold the Big-Data
When you have billions of records of data, using Calgary data files to store your data in Alteryx is a great idea. One of the reasons for this is that you can index your data, which allows you to rapidly retrieve results. In this section, I’ll show how this is done and how long it takes to happen. In this case, I’ll use data from an actual project to demonstrate the performance of Alteryx.
In some of my projects, if the data is big enough, I choose to store my incoming data in monthly Calgary files. When I do, it is because I am receiving hundreds of millions of records of data per month.
In one example I have, a recent month of data contained 400 million records of data, which translated into a 44 gigabyte Calgary file (May 2018). The creation of this file, with 5 indices, took 1 hour and 17 minutes.
In general, as shown in Figure 4, the Calgary file creation process averages about 600 megabtyes per minute for the number of indices I chose. It took less than 14 hours to create 480 Gb of monthly Calgary files. In another example I did, it took about 14 hours to create nearly 600 Gb of Calgary files, or about 700 Mb per minute. The time it takes to create these files is time well-spent, as you will see.
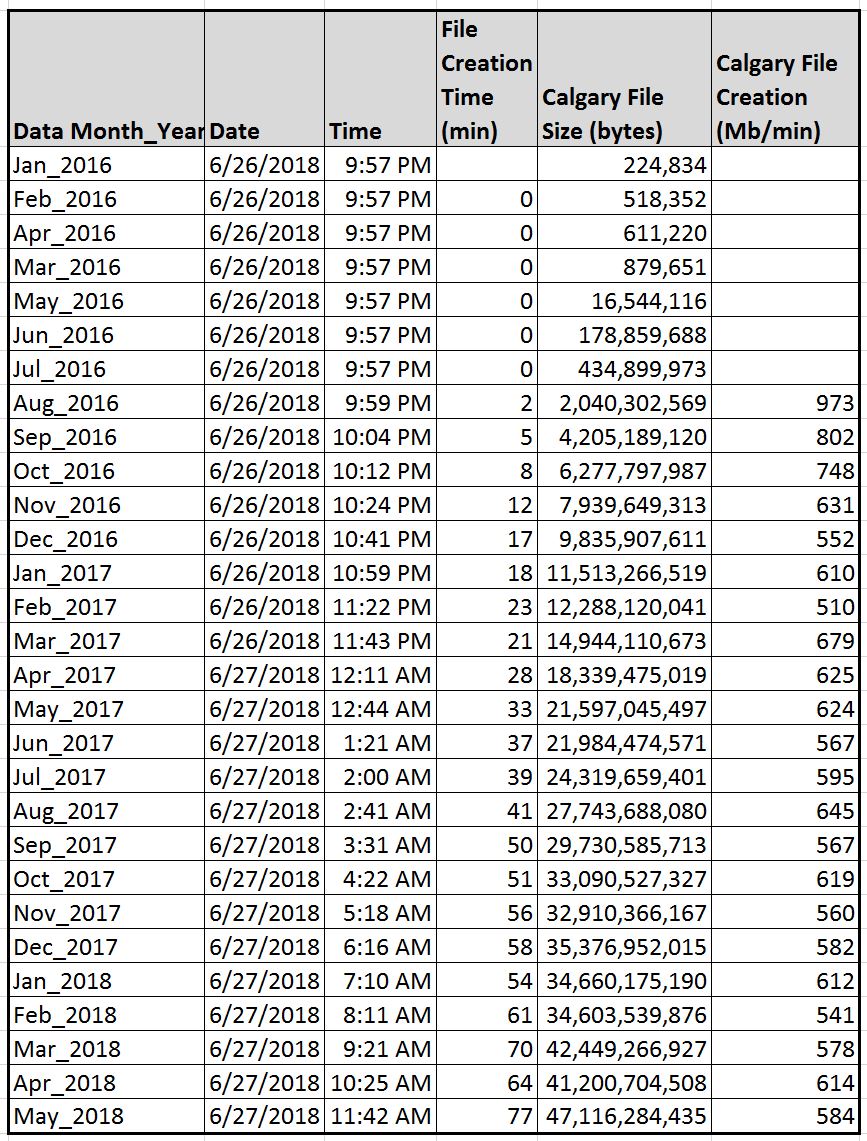
Figure 4 – This Calgary file creation benchmark study indicates an average of about 600 Mb/min for writing Calgary data files, with 5 indices in this case.
The creation of a Calgary file is very easy. If you watch the short video shown below, you will learn about you can use a batch macro to convert your Alteryx (.xydb) files into Calgary (.cydb) files.
Taking Advantage of Your Data Using the Calgary Join Tool
When you are looking for a needle in a haystack of data, data size is your arch-enemy. As your source data grows, retrieving what you are looking for becomes increasingly time-consuming, unless you use the techniques I’m talking about in this article.
To prove my point of how great Calgary files are, I did a little test using the April 2017 Calgary file shown in Figure 4. This 17 Gb data file contains over 156M records generated from about 1M data sources. From this file, I wanted to pull information for the days that included 614 discrete events (measured down to hh:mm:ss). In other words, I needed to find a few needles in a big haystack.
When I did a standard Alteryx join operations using two variables that were indexed in the Calgary file, it took 11 minutes and 45 seconds to retrieve the 2254 records that represented the daily data from those 614 discrete events. That’s really good performance.
However, when I used the Calgary join tool using the same two indexed variables, it took 1 minute and 1 second to return the 2254 records. This is a 92% reduction in the time required to complete the query. Now that I AWESOME performance!
Nice Features of The Calgary Join Tool
Two really nice features of the Calgary join tool is that it also will bind the lookup data to the Calgary data, and will even show the records that were not matched. Effectively this gives you both the left join and inner join results in one output table.
The configuration of the Calgary join tool is shown in Figure 5. The two indexed fields I used are shown as bold in the Input Fields of Query Criteria tab, the checkbox allows the unmatched records to be included in the output, and the Action command binds the Calgary data to the input records. As usual, the Calgary join tool is expertly crafted and does exactly what I wanted to do, saving me hours of search time across my entire data source.
Finally, the data that you are searching for is prepared in a file that you send into the Calgary join tool. At a minimum, it will contain the fields that you have set as your indexes. In this case, I’m using the day of the event and another field. I’m not showing this simple workflow here, but it is only one input file pointing into the Calgary tool. The only tricky part of this for me was recognizing how to double click the input fields to choose them as an index field. The complete workflow I used for an example is shown in the next section.

Figure 5 – The Calgary join tool configuration that allowed me to extract exactly what I wanted in a fraction of the time. By setting a double index (the bolded input fields), the data set that was returned in 1 minute was exactly what was needed.
The Big Data Extraction Method
Once you have all the Calgary files created and you have your list of events that you want to find in the Calgary files, you can assemble a workflow that takes advantage of the work you created to get to this point. Figure 6 shows one of my workflows that searches for over 13,000 events across 17 months, with the Calgary files holding over 4.1 billion time series events.

What this workflow accomplishes is to locate all the time series events that occurred on the same day the singular events you are searching for. The filtering by month will only send the events that occurred in that month to the Calgary join tool. By cascading the input file through the 17 monthly filters, the events are sent to the proper Calgary files for lookup.
You may wonder why I decided to partition and store the data by month. The reason is that this particular data source is growing rapidly. It already has over 400 million records within a month, and the equivalent Calgary file for this is approaching 50 Gb.
I don’t like to create really huge files because of the added risk of file corruption. If something happens in one month, I can re-create the file from the source data without too much trouble. This paranoia is probably an artifact of my previous career, where file corruptions were more commonplace. In all my experience with Alteryx, I have never had any issues with an Alteryx created file, but I don’t want to test my luck by writing a 480 or 600 Gb Calgary file!
Another reason for storing the data by month is that it can make my retrieval much quicker if I am able to limit how much data I have to search through. If my data occurs in May 2018, then I only have to search one Calgary file rather than going through all 17 months if I had written the data to one file. This is part of the strategy for making quicking data retrieval possible.
The Summary
To summarize what we accomplished here, this workflow reduced the data size from over 4.1 billion records to about 47,000 records for the 13,000 events I was searching for. The run-time for this workflow was less than 45 minutes. This is astounding and very efficient. How long do you think this would take you to do using methods you currently use?
In this case, I was even able to use the other events that occurred during the days of interest to investigate some behaviors stored in the data. You can choose to keep all the events from that day, or just the ones that include the events you are trying to find.The key to this success is that the Calgary searching method uses indexing of two variables to very quickly locate the data. Once you have the data limited as described above, you only need to test 47,000 records to see if the discrete events are contained between the starting and stopping times of the time series events. That part of the problem is trivial, but limiting the data is not.
Final Thoughts
One of the greatest features of Alteryx is its ability to work with any kind of data and it doesn’t matter if the data is small or big. The tools developed for Alteryx were created without specific assumptions and restrictions, which makes its utility so far-reaching. However, with such widespread capability, it takes a while to develop use cases that tap into the full power of Alteryx. Such is the Calgary load and Calgary join tools I covered here.
Unless you are working with really big data sources, you might not ever need to write Calgary files. For me, it took years until the need became apparent. The only reason I even know about this technique has to do with a short conversation I recently had with Ned Harding.
As I pondered how to do this big job of searching for needles in a haystack, I proposed a method to Ned. He countered with another approach I could try. After he said that, he almost innocently told me about the Calgary load tool. Since I had never used it, I was intrigued by the possibility of using it.
Once I did the testing, I instantly knew how powerful this methodology is. To me, Calgary data sources were only a part of Alteryx because of the demographic data I have used in the past. I thought that Calgary files were proprietary in nature. I didn’t realize I could create my own.
Now thanks to the mastermind of Alteryx named Ned, I have an improved vision of what I can do with Alteryx to handle really large data. The upcoming months are going to be fun, thanks to Ned!



Thanks for sharing this; I was not aware of Calgary files or what they could do. I have a similar “big data” problem I’m working on–not nearly as big as the one you describe, but I think that I can use this approach to solve it.
Pingback: Why @Alteryx and @Tableau Are Sticky Products | Data Blends
Pingback: How To Rapidly Retrieve Data From Large Data Sets Using @Alteryx | Data Blends
Can I ask how big your hard drive was when you were creating these Calgary databases? I’m trying to convert one of my files with ~100 million rows (about 8GB in .yxdb format) into a Calgary database with a handful of indices, and I keep getting error messages that I don’t have enough free space on my hard drive even though I have just under 27GB free.
Hi Jordan,
My primary HD is 8 tb, with about 4 tb available. This drive is separate from my Alteryx installation. You might need to check the space availability on the drive that holds Alteryx because temp files might be being created where there isn’t enough space. I believe that you can configure/specify the location of temp files, although it’s been years since I’ve done that.
I have never experienced the error you are describing. Let me know if you haven’t been able to resolve this issue.
Ken
Hi Ken,
I ended up trying it on a different drive at work and it worked just fine.
Thanks for your write-up on these databases. Very informative. I am still astounded by how much faster they are than .yxdb files.
Best,
Jordan