Background
In part 1 of this article, I am going to show how Alteryx continues to improve its software offerings. Alteryx has historically been known as having a great computational engine (E1) because of the meticulous attention to detail and superb testing that was completed while Alteryx was developed.
Alteryx has now taken this existing masterpiece of a computational engine and made it even better. That was not an easy thing to do and it was a multi-year effort to complete. In a recent product release (version 2020.2 on June 15, 2020), Alteryx has quietly released a beast known as AMP.
The AMP nomenclature stands for Alteryx Multi-threaded Processing. What this means is that Alteryx workflows will now take advantage of all the computational cores on a computer. With AMP, the time needed to complete the data work will be less than before. Saving time is saving money. This allows us to get more done during the workday. There are many advantages to having better computational speed without having to buy more expensive computer equipment. That saves money, too.
In part 2 of this article, I will show how Tableau continues to shine by ingesting the big data sources that can be created by programs like Alteryx. Just because we have 1B+ lines of data, we must be able to visually render data in a reasonable amount of time in ways that make sense to us.
To summarize, these articles will be part benchmark results, part experimental results, and part education. As typical, I might have to be somewhat fuzzy in explaining the true meaning of the data I’ll be showing. As always, these results are real-world, truthful results with no hanky-panky going on behind the scenes. I just love writing about these great products!
The Computer Used for Testing
Let’s get right to it. I have a relatively cheap Dell desktop computer that cost about $800 at Costco (Figure 1). This thing can outperform the first 16-node, multi-million dollar supercomputer I ever worked on at the Oak Ridge National Lab back in the 1980’s. My oh my, how fast things change.

This little computer has an eight generation i7 Intel processor (i7-8700 CPU @ 3.2 Ghz) that features 6 computational cores and 12 threads. The CPU sells for about $300 and is from 2017. I upgraded the memory to 64 Gb, added a 2Tb SSD drive for speed, and an 8 Tb hard drive for storage. The total package is less than $1400.
Even with this modest investment, I can rip through big data projects with sufficient speed to keep things fun. A few months ago, I wrote about working with billions of records of weather data from Australia. That work was completed on this little computer. In this article series, other examples I show have also been done on this computer.
The Alteryx AMP Engine
Figure 2 shows the CPU usage for a workflow that was running with the E1 engine. Notice how the 12 cores are not being fully utilized? The sporadic CPU usage is typical of non-hyper-threaded applications.

In contrast to the CPU usage of E1, the AMP CPU usage shown in Figure 3 is 100% pegged. All the threads are ripping at maximum capacity, giving us theoretically the best performance possible on this little computer.
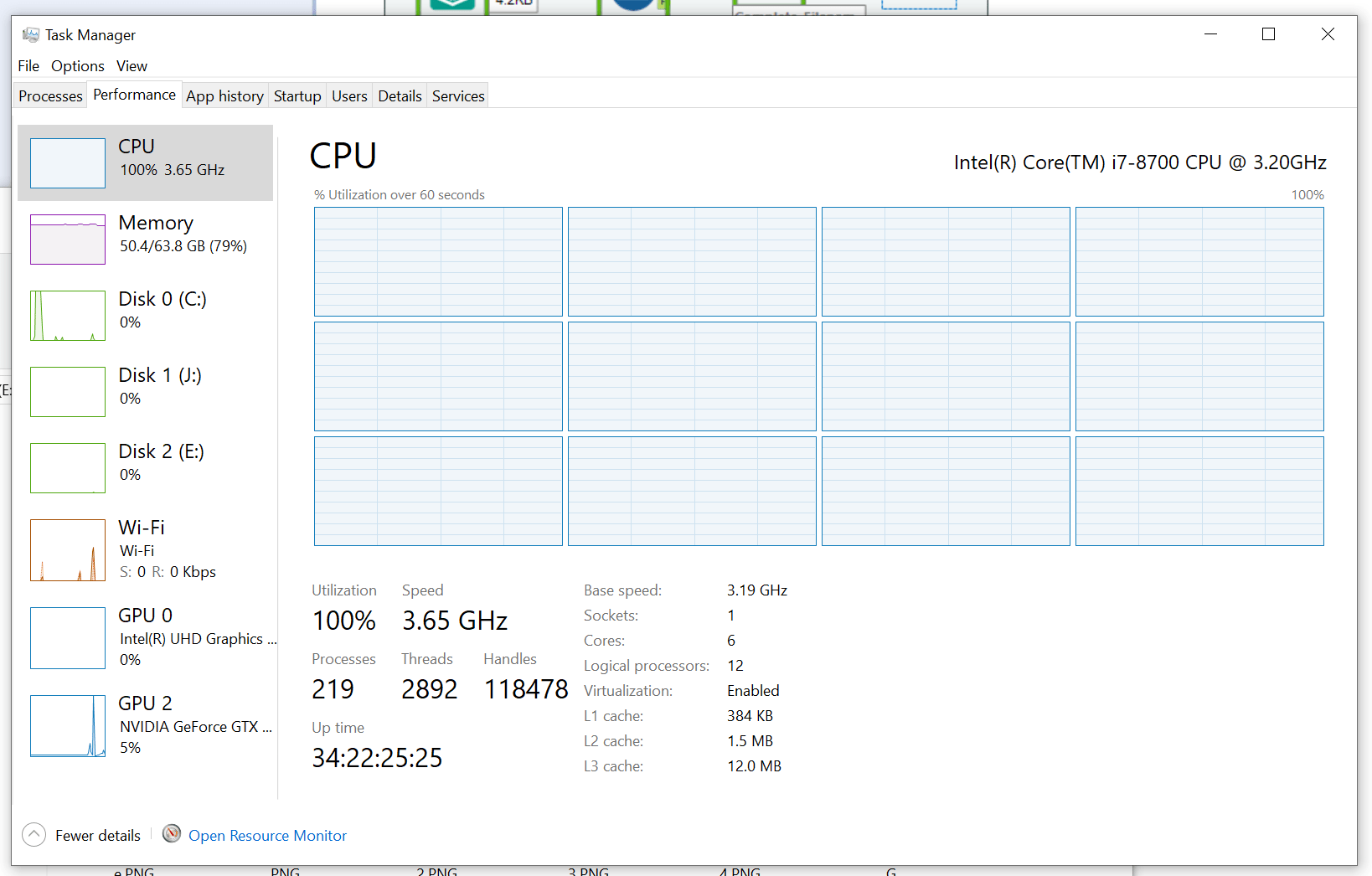
We can see that over 50 Gb of RAM is consumed while the threads are all max capacity. Please understand that this type of performance does not always happen during an AMP workflow execution. There are times when data is being loaded or other events are happening when the CPU usage patterns are not all at 100%. This example just happened to be while the workflow was running through a big data set and pure computations were occurring.
The first time you turn on an AMP workflow like this, the computer fans rev up and the make sounds like a jet engine getting ready to take-off. You feel a visceral reaction to this moment in time. In my mind, I had a vision of Arnold Schwarzenegger saying to me, “AMP pumps you up!”
Now I bet you are wondering how this translates into better computational performance? What I can tell you is that I have now run many tests with the new engine and the results have always been great, even though not all the Alteryx tools have been optimized for usage in the AMP engine. To keep this article a reasonable length, I will discuss a small test followed by a huge multi-day test. I’ll be releasing more insights over time on the computational improvements I am seeing.
Test 1 – Comparing tool usage (small test)
In the small test, I theorized that I could achieve a significant computational improvement by how I wrote the workflow (which tools I chose to do the job). It turns out I was right.
In the first part of the test, by using an approach I call “cascading filters”, the improvement was a 10.6x increase in performance. Yes, that is over a 900% increase. A workflow that took 3 minutes and 53 seconds in the E1 engine took only 21.8 seconds in the AMP engine. That is nice but it is only for a small workflow.
This improvement had a lot to do with how I designed the workflow. In this case, the improvement occurred because I encouraged Alteryx to spread the work out over several processors by using a series of filters to split the data stream and place data into discrete buckets. As I expected, this approach was able to take beautiful advantage of the multiple cores on my little computer.
I built another workflow that did the same tasks by using a big if-then-else block instead of cascading filters. The improvement in this case was 2.7x (1:59 vs 44 seconds). That workflow was not designed to take advantage of the multiple cores because all the work was being done in one formula tool. Even with that being the case, the workflow was still 170% faster!
What the small test taught me is that the AMP engine now gives us the ability to optimize workflows by intelligently using tools that can take advantage of the cores on a computer.
The first time you turn on a workflow like this, the computer fans rev up and make sounds like a jet engine getting ready to take-off. In my mind, I had a vision of Arnold Schwarzenegger saying to me, “AMP pumps you up!”
Now turn to Page 3 to read about the big study!



Pingback: The Alteryx Advantages | Data Blends